
アクター
`アクターモデル`は並行分散システムを作るための高度な抽象を提供します。アクターモデルを用いることで開発者は明示的なロックやスレッドの管理を行う労力を軽減した上で信頼性のある並行並列なシステムを作ることができます。アクターは Cal Herwitt が1973年に論文として発表したものですが、Erlangによって世に広められ、この成功例として Ericsson 社による高い並行性と信頼性を持つ電気通信システムの構築が挙げられます。
Akka のアクターは Erlang からシンタックスを拝借した Scala のアクターと似ています。
アクターの生成
注釈
Akka では全てのアクターが親となるアクターに監視され、同時に子供のアクターの supervisor になる(可能性がある)という方式をとっています。この方式については アクターシステム や スーパービジョン と モニタリング あるいは アクターの参照、パス、アドレス といった記事を参考に読んでみるとよいでしょう。
アクターのクラスを定義する
アクターは Actor という基本traitを拡張することで実装することができます。また、ここで:meth:`receive`というメソッドを実装する必要があります。:meth:`receive`というメソッドはcase文の塊で(この型は`PartialFunction[Any, Unit]``です)、Scalaのパターンマッチングを使ってアクターがどのようなメッセージを処理できるかということとそのメッセージがどのように処理されるかということを定義します。
以下はこのサンプルコードです。
import akka.actor.Actor
import akka.actor.Props
import akka.event.Logging
class MyActor extends Actor {
val log = Logging(context.system, this)
def receive = {
case "test" => log.info("received test")
case _ => log.info("received unknown message")
}
}
Akkaのアクターの``receive``メッセージループは網羅的であるということに注意してください。これはErlangやScala言語組み込みのアクターとは異なっています。つまり受け取ることのできる全てのメッセージについてのパターンマッチを書く必要があり、未知のメッセージを処理したい場合はデフォルトのcaseを書かなければいけません。これを行わなかった場合は ``ActorSystem``の``EventStream``に`akka.actor.UnhandledMessage(message, sender, recipient)``が発行されます。
また、振る舞いの戻り値の型が``Unit``であることにも注意してください。アクターが受け取ったメッセージに対して応答を返す場合、後で説明するようにこれを明示的に行う必要があります。
:meth:`receive`メソッドの結果は部分関数であり、アクターの"初期の振る舞い"とみなされます。アクターが生成された後でどのように振る舞いを変えるかということについての詳しい情報は`Become/Unbecome`_を参照してください。
Props
:class:`Propsはアクターを生成するときのオプションを指定するための設定クラスです。このクラスのインスタンスは不変なので気軽に共有することができるアクターを生成するためのレシピと考えることができます。また、このレシピにはデプロイに関係した情報(例えばどのdispatcherを使うかとかいったもの)も含めることができます。
import akka.actor.Props
val props1 = Props[MyActor]
val props2 = Props(new ActorWithArgs("arg")) // careful, see below
val props3 = Props(classOf[ActorWithArgs], "arg") // no support for value class arguments
二つ目のやり方は生成する:class:`Actor`にどのように引数を渡すかということを例示していますが、後で説明するように、アクターの外側のみで用いるべきやり方です。
最後のやり方はアクターのコンストラクタに引数を渡す場合にどのようなコンテクストでも使うことができるやり方です。Propsオブジェクトの中でどのコンストラクタを用いるべきかということを調べて、適当なコンストラクタが見つからなかった場合や複数のコンストラクタにマッチしてしまった場合には:class:IllegalArgumentException となってしまいます。
注釈
アクターのコンストラクタが引数として値クラスを受け取る場合、アクターの:class:`Props`を作るための推奨される手法はサポートされていません。
危険な方法
// NOT RECOMMENDED within another actor:
// encourages to close over enclosing class
val props7 = Props(new MyActor)
このメソッドはアクターの中で使わないほうがいいです。このメソッドによって呼び出し元のアクターのスコープをリークしてしまい、:class:`Props`が永続化不可になってしまい競合状態(アクターのカプセル化が壊されるということ)を引き起こす可能性があります。将来的にはマクロを使って同じようなシンタックスを使っても問題が起きないようにする予定ですが、現在のところこの方式は非推奨としたほうがいいでしょう。一方で、"推奨される手法"のところに書いてあるアクターのコンパニオンオブジェクトにある:class:`Props`のファクトリを使うというやり方は特に問題がありません。
このメソッドを使うユースケースは二つあります。一つはアクターのコンストラクタに引数を渡したい場合ですが、これは新しくできた:meth:`Props.apply(clazz, args)`を上に書いてあるとおりに使うか下に書いてあるような推奨される手法を使うことで解決できます。もう一つは"その場で"無名のアクターを作る場合ですが、これはそのようなアクターにちゃんと名前を付けてあげることで解決できます。(アクターがトップレベルの``object``として宣言されていない場合、それに紐づくインスタンスの"this"の参照がクラスの最初の引数に渡されてしまいます)
警告
あるアクターを別のアクターの中で宣言することは非常に危険でアクターのカプセル化を破壊してしまいます。アクターの"this"への参照を:class:`Props`に渡してしまわないように注意してください。
エッジケース
:class:`Props`を使ったアクターの生成には二つのエッジケースがあります。
引数に:class:`AnyVal`を受け取るアクター
case class MyValueClass(v: Int) extends AnyVal
class ValueActor(value: MyValueClass) extends Actor {
def receive = {
case multiplier: Long => sender() ! (value.v * multiplier)
}
}
val valueClassProp = Props(classOf[ValueActor], MyValueClass(5)) // Unsupported
デフォルトのコンストラクタ引数を持つアクター
class DefaultValueActor(a: Int, b: Int = 5) extends Actor {
def receive = {
case x: Int => sender() ! ((a + x) * b)
}
}
val defaultValueProp1 = Props(classOf[DefaultValueActor], 2.0) // Unsupported
class DefaultValueActor2(b: Int = 5) extends Actor {
def receive = {
case x: Int => sender() ! (x * b)
}
}
val defaultValueProp2 = Props[DefaultValueActor2] // Unsupported
val defaultValueProp3 = Props(classOf[DefaultValueActor2]) // Unsupported
どちらのケースもコンストラクターを見つけられない状態になってしまって IllegalArgumentException がスローされます。
次のセクションでは:class:`Actor`のpropを作るための推奨される手法を説明します。同時にこの手法はこれらのエッジケースに対する回避策になります。
推奨される手法
全ての:class:`Actor`のコンパニオンオブジェクトの中で:class:`Props`の生成を適切に行うことを補助するようなファクトリメソッドを提供するのは良いアイディアです。コンパニオンオブジェクトの中のコードブロックはcall-by-nameなメソッド引数の中にリークしないので、こうしたファクトリメソッドを使えば``Props.apply(...)``を使うことによる落とし穴に嵌ることを避けることができます。
object DemoActor {
/**
* Create Props for an actor of this type.
*
* @param magicNumber The magic number to be passed to this actor’s constructor.
* @return a Props for creating this actor, which can then be further configured
* (e.g. calling `.withDispatcher()` on it)
*/
def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber))
}
class DemoActor(magicNumber: Int) extends Actor {
def receive = {
case x: Int => sender() ! (x + magicNumber)
}
}
class SomeOtherActor extends Actor {
// Props(new DemoActor(42)) would not be safe
context.actorOf(DemoActor.props(42), "demo")
// ...
}
もう一つの良い手法として、コンパニオンオブジェクトの中でそのアクターが受け取ることができるメッセージを宣言するというものがあります。このようにしておくと、アクターがどのようなメッセージを受け取ることができるのかがわかりやすくなります。
object MyActor {
case class Greeting(from: String)
case object Goodbye
}
class MyActor extends Actor with ActorLogging {
import MyActor._
def receive = {
case Greeting(greeter) => log.info(s"I was greeted by $greeter.")
case Goodbye => log.info("Someone said goodbye to me.")
}
}
Propsを使ったアクターの生成
アクターは:class:`Props`のインスタンスを:class:`ActorSystem`や:class:`ActorContext`が持っている:meth:`actorOf`というファクトリメソッドに渡すことで生成できます。
import akka.actor.ActorSystem
// ActorSystem is a heavy object: create only one per application
val system = ActorSystem("mySystem")
val myActor = system.actorOf(Props[MyActor], "myactor2")
:class:`ActorSystem`を使うとトップレベルのアクターを生成できます。トップレベルのアクターはアクターシステムが提供しているガーディアンアクターによって監視されます。一方でコンテクストから生成したアクターはそのアクターの子アクターになります。
class FirstActor extends Actor {
val child = context.actorOf(Props[MyActor], name = "myChild")
// plus some behavior ...
}
子供から孫といった階層を作るようにしてください。そのようにすることでアプリケーションの論理的なエラー処理の構造を作ることができます。詳しくは:ref:`actor-systems`を参照してください。
:meth:`actorOf`を呼ぶことで:class:`ActorRef`のインスタンスを得ることができます。:class:`ActorRef`はアクターのインスタンスとつながっていて、アクターと対話するための唯一の手段となります。:class:`ActorRef`は不変でそれが表現しているアクターと一対一の関係を持っています。:class:`ActorRef`は永続化可能なのでネットワークを介することができます。つまり、シリアライズしたインスタンスをリモートのホストに送信した場合、元のノードのアクターをネットワークを超えて表現することができます。
nameパラメータはオプションですがアクターには名前を与えた方がよいでしょう。なぜなら、アクターの名前はログメッセージでアクターを識別するために用いるからです。アクターの名前は空文字や"$"から始まる文字列は許可されていませんが、そうした名前がURLにエンコードされた文字には含まれることがあります。(例えば、"%20"は空白文字です。)もじ与えられた名前が既に同じ親を持つ他の子アクターが利用していた場合、:class:`InvalidActorNameException`がスローされます。
アクターは生成されたら非同期に自動的に開始されます。
コンストラクタ引数の値クラス
アクターのpropsのインスタンスを得るための推奨される方法ではアクターのどのコンストラクタを呼ぶのが正しいのかを調べるためにリフレクションを使っています。この技術的な制限のため、値クラスを引き数として受け取るコンストラクタの利用はサポートされていません。こういったケースでは値クラスの中の値をあらかじめ取り出しておくかコンストラクタを直接呼び出すようなpropsを作る必要があります。
class Argument(val value: String) extends AnyVal
class ValueClassActor(arg: Argument) extends Actor {
def receive = { case _ => () }
}
object ValueClassActor {
def props1(arg: Argument) = Props(classOf[ValueClassActor], arg) // fails at runtime
def props2(arg: Argument) = Props(classOf[ValueClassActor], arg.value) // ok
def props3(arg: Argument) = Props(new ValueClassActor(arg)) // ok
}
依存性の注入
アクターがコンストラクタで引数を受け取る場合、`すでに述べたように`__それは:class:`Props`の生成の中で利用する必要があります。しかし、ファクトリメソッドを用意していたとしても直接コンストラクタを使うケースがあります。例えば依存性の注入を行うフレームワークがコンストラクタの引数を調べる場合です。
import akka.actor.IndirectActorProducer
class DependencyInjector(applicationContext: AnyRef, beanName: String)
extends IndirectActorProducer {
override def actorClass = classOf[Actor]
override def produce =
// obtain fresh Actor instance from DI framework ...
}
val actorRef = system.actorOf(
Props(classOf[DependencyInjector], applicationContext, "hello"),
"helloBean")
警告
:class:`IndirectActorProducer`が必要な時に``lazy val``などを使って常に同じインスタンスを得たいと思うかもしれません。しかし、同じアクターのインスタンスを使いまわすということはは:ref:`supervision-restart`で述べてるようなアクターの再起動といった概念と衝突するためサポートされていません。
依存性の注入を行うフレームワークを使う場合、アクターのbeanはシングルトンスコープであることは*許可されません*。
依存性の注入のためのテクニックや依存性注入を行うフレームワークとの統合については`Using Akka with Dependency Injection <http://letitcrash.com/post/55958814293/akka-dependency-injection>`_ guidelineやLightbend Activatorの中の`Akka Java Spring <http://www.lightbend.com/activator/template/akka-java-spring>`_ tutorialにより詳しい情報があります。
Inbox
アクターの外側のコードからアクターと通信をする場合、``ask``パターン(後で出てきます)を使うのが一つの方法ですが、それを使えない場合が二つあります。一つは複数のメッセージを受け取るような場合(例えば通知サービスとして実装されている:class:`ActorRef`を購読する場合)で、もう一つはActorのライフサイクルをwatchしている場合です。こういった場合のために:class:`Inbox`というクラスが用意されています。
このコードでは:class:`Inbox`から:class:`Inbox`への暗黙的な変換が行われています。つまりこの例ではsenderへの参照は暗黙的に:class:`Inbox`に対するものになります。このようにすることで最後の行に書かれているようなやり方で応答を受け取ることができます。アクターをwatchする方法も簡単です。
Actor API
Actor traitには、抽象メソッドが一つしか定義されていません。それはすでに述べた:meth:`receive`メソッドで、アクターの振る舞いを実装するメソッドです。
現在のアクターの振る舞いが受け取ったメッセージを処理できない場合、:meth:`unhandled`が呼ばれ、そのデフォルトの実装では``akka.actor.UnhandledMessage(message, sender, recipient)``をアクターシステムのイベントストリームに発行します(これは``akka.actor.debug.unhandled``という設定を``on``にすることで実際のデバッグのメッセージに変換されます)。
Actor traitには他にも以下のようなメソッドがあります。
selfこのアクター自身の:class:`ActorRef`への参照sender最後に受け取ったメッセージの送信者となるActorへの参照。通常:ref:`Actor.Reply`で述べているような用途で使います。supervisorStrategyユーザがオーバーライド可能な子アクターをどう監視するかというストラテジーの定義このストラテジーは戦略を決めるための関数の中でアクターの内部状態にアクセスするため、通常アクターの中で宣言します。障害は supervisor にメッセージとして通知され、他のメッセージと同じように処理されます。(通常の振る舞いの外側に置かれるものの)この関数の中ではアクター内部の全ての値や変数、"sender"への参照を利用することができます。(これは直接の子アクターが報告した障害の情報に含まれます。元となる障害が孫以上の子孫の場合でも障害が起きた階層の sender が報告されます。)
contextアクターや現在のメッセージに関するコンテクスト情報を参照できます。これには以下のようなものがあります。子アクターを作るためのファクトリメソッド(
actorOf)アクターが所属しているシステム
supervisorである親アクター
監視している子アクター
ライフサイクルの監視
:ref:`Actor.Hotswap`に書かれている動的に置き換え可能な振る舞いのスタック
:obj:`context`のメンバーをimportすることで"context"というプレフィックスなしにそのメンバにアクセスすることができます。
class FirstActor extends Actor {
import context._
val myActor = actorOf(Props[MyActor], name = "myactor")
def receive = {
case x => myActor ! x
}
}
ここまででまだ残っているアクセス可能なメソッドはユーザがオーバーライドすることで以下の述べるアクターのライフサイクルにフックすることができるメソッドです。
ここまでに紹介した実装は:class:Actor traitを使うことでデフォルトで利用できます。
アクターのライフサクル
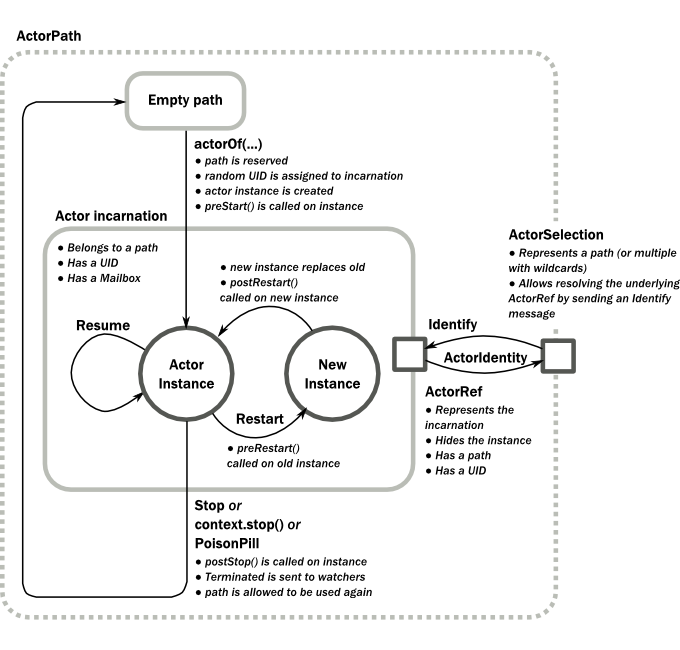
アクターシステムにおけるパスは生存しているアクターによって占有されている"場所"を表現しています。始めは(システムによって初期化されたアクターを除き)パスは空になっています。 actorOf() を呼びだすと Prop で表現されたアクターの*インカーネーション*が与えられたパスに生成されます。アクターのインカーネーションはパスと UID によって識別されます。再起動が行われたときには Actor のインスタンスは置き換えられますが、インカーネーションの方は置き換えられないので UID は同じものになります。
アクターのインカーネーションのライフサイクルはアクターが停止した時に終わります。この時、これに対応したライフサイクルの終了イベントが呼ばれ、これを watch しているアクターに停止が通知されます。インカーネーションが停止したのち、インカーネーションのパスは再び actorOf() を使って再利用することができるようになります。この場合新しいインカーネーションの名前は前のものと同じですがUIDは別のものになります。アクターは自分自身や他のアクター、あるいは``ActorSystem``によって停止されることがあります。(:ref:`stopping-actors-scala`を参照)
注釈
アクターは参照されなくなったとしても自動的に停止することはないという点は重要です。生成された全てのアクターは明示的に破棄する必要があります。ただし親のアクターを停止する場合、そのアクターが生成した全ての子供のアクターも停止されるのでこの点は単純です。
``ActorRef``はただ単に与えられたパスを表現しているのではなくいつでもインカーネーション(パスとUID)を表現しています。つまりアクターを停止して同じ名前のアクターを生成した場合、新しく生成した``ActorRef``は古いインカーネーションでなく新しいインカーネーションを指しています。
一方で ActorSelection はパスを示していて(ワイルドカードを使った場合は複数のパスを指します。)、現在そのパスを持っているのがどのインカーネーションなのかを完全に識別することができます。このため ActorSelection を watch することはできません。パスに存在するインカーネーションを watch するためには、ActorSelection に対して Identity メッセージを送信し ActorSelection から応答として ActorIdentity を受け取り、その中に含まれる正しい参照(actorSelection-scala`を参照)を使って現在のインカーネーションの ``ActorRef` を解決します。 ActorSelection が持つ resolveOne を使うとパスにマッチした ActorRef の Future が戻されるので同じようなことができます。
ライフサイクルの監視、DeathWatch
他のアクターの停止を知るために(例えば、永久に停止された場合や一時的ではない障害によって再起動された場合など)、アクターは他のアクターが停止時に発する Terminated メッセージを受け取るようにすることができます。(Stopping Actors`_も参照のこと)この機能はアクターシステムの :class:`DeathWatch というコンポーネントによって提供されています。
モニターを登録するのは簡単です。
import akka.actor.{ Actor, Props, Terminated }
class WatchActor extends Actor {
val child = context.actorOf(Props.empty, "child")
context.watch(child) // <-- this is the only call needed for registration
var lastSender = context.system.deadLetters
def receive = {
case "kill" =>
context.stop(child); lastSender = sender()
case Terminated(`child`) => lastSender ! "finished"
}
}
Terminated メッセージは登録や停止がどのような順番で起きたかとは独立して生成されることに注意してください。典型的な例として、監視を行うアクターは例え監視の登録を行った時点ですでに監視対象のアクターが停止されていたとしても Treminated メッセージを受け取ることになります。
監視の登録を複数回行うことが必ずしも複数のメッセージを作ることになるわけではありませんが、こうしたメッセージを正確に一度受け取ることができる保障はありません。監視対象のアクターの停止メッセージが作られてキューに入ってから、このメッセージが処理される前に他のところで登録が行われたら、二つ目のメッセージがキューに入ります。何故なら既に停止したアクターの監視を登録すると、直ちに: class:Terminated が生成されるためです。
同じようなことが他のアクターの生存監視を context.unwatch(target) を使ってやめた場合にも起こりえます。これは例え Terminated メッセージがメールボックスに入っていたとしても、unwatch`の呼び出しの後には監視を停止したアクターの :class:`Terminated メッセージは処理されないためです。
Start Hook
アクターが正しく起動すると、 preStart というメソッドが呼び出されます。
override def preStart() {
child = context.actorOf(Props[MyActor], "child")
}
このメソッドはアクタがーが初めに生成されたときに呼び出されます。アクターが再起動したときには postRestart のデフォルトの実装がこのメソッドの呼び出しを行いますが、このメソッドをオーバーライドすることによって初期化のコードを一度だけ呼び出されるようにするのか、再起動のたびに呼び出されるようにするのかを選択することができます。アクターのコンストラクタの中の初期化コードはアクターが生成された時や再起動したときに常に呼び出されます。
Restart Hook
全てのアクターは、例えば他のアクターによるエラー処理のストラテジーに紐づくことによって監視されています。アクターがメッセージを処理しているときに例外をスローした場合は再起動が行われます。(スーパービジョン と モニタリング を参照)この再起動は上記に挙げたフック処理のトリガになります。
古いアクターには
preRestartの中で再起動の原因となった例外と例外を引き起こしたメッセージが通知されます。後者のメッセージは、例えばsupervisorが例外を補足せずにそれより上位のsupervisorに再起動された場合やアクターが兄弟関係にあるアクターの障害によって再起動された場合など、再起動の原因となったのがメッセージの処理ではない場合にはNoneが受け渡されます。メッセージが受け渡された場合には、メッセージのsenderもいつもと同じやり方で取得することができます。(これは、``sender``の呼び出しを行うことでできます)このメソッドは新しいアクターのインスタンスなどへの引き継ぎのためにクリーンアップを行うのにもっともよい場所です。デフォルトの実装では全ての子アクターを停止して
postStopを呼び出すようになっています。新しいインスタンスを生成するために
actorOfの呼び出し時から引き継いだ初期化のファクトリを利用します。新しく生成したアクターの
postRestartに再起動の原因となった例外を受け渡して呼び出します。デフォルトの実装ではpreStartの呼び出しを行って通常のアクターの開始と同じように振る舞います。
アクターの再起動では実際のアクターのオブジェクトが入れ替わるだけです。再起動がメールボックの内容に影響を及ぼすことはないので、メッセージの処理は :metho:`postRestart` の処理が終わった後に再開されます。例外の原因となったメッセージを再び受け取ることはありません。再起動中にアクターが受け取ったメッセージは通常メールボックスには入りません。
警告
障害の通知とユーザのメッセージの相対的な順番が決定的ではないことに注意してください。特に、親のアクターによって子アクターが障害が起きる前に受け取った最後のメッセージを処理する前に再起動してしまうことがあります。詳細については ディスカッション: メッセージの順序 を参照してください。
Stop Hook
アクターが停止した後には、そのアクターの postStop フックが呼び出されるので、これを使って他のサービスからこのアクターを登録解除するといった処理を行うようにします。ここのフックはこのアクターに対するメッセージのキューイングが利用できなくなってから呼び出されることが保障されています。停止されたアクターに送信したメッセージは ActorSystem の deadLetters にリダイレクトされるようになります。
Actor Selectionを使ったアクターの識別
アクターの参照、パス、アドレス で述べたように、アクターはそれぞれ一意な論理パスを持っていて、子供から親を辿ってアクターシステムのルートにまで遡ることができることができます。また、アクターは物理的なパスも持っていますが、監視のチェーンの中にリモートのsupervisorが存在する場合には論理的なパスと異なることがあります。これらのパスはリモートからメッセージを受け取った時に受信者を検索するのに利用されたりしますが、もっと直接的な利点があります。アクターは絶対パスもしくは相対パスを--これらは論理的なものと物理的なものがあります--を使ってほかのアクターを検索し ActorSelection を使ってその結果を受け取ることができます。
// will look up this absolute path
context.actorSelection("/user/serviceA/aggregator")
// will look up sibling beneath same supervisor
context.actorSelection("../joe")
注釈
通常、アクターの通信はActorSelectionに頼らずにActorRefを使う方が望ましいです。ただし、次の場合は例外です。
メッセージを送信するのに At-Least-Once Delivery の手法を用いる場合
リモートシステムとの始めの通信を行う場合
上記以外のケースでは、親から子にActorRefを渡したり、ActorRefへの参照を含メッセージを他のアクターに送信するなど、アクターの生成時や初期化時にActorRefを受け渡す方法があります。
与えられたパスは java.net.URI に解決されます。つまり基本的にパスは"/"で区切られたパスの要素からなります。パスが "/" から始まる場合はルートガーディアンから辿ることのできる絶対パスになります。(ルートガーディアンは "/user" の親です。) それ以外の場合は現在のアクターから辿るパスになります。パスの要素が .. となっている場合はその前のパスで解決されたアクターのsupervisorのパスへと"戻り"、そこからその子アクターを"辿り"ます。 .. というアクターのパスが表現しているのがいつも論理的な構造でsupervisorを表しているということには注意が必要です。
アクターを選択するするパス要素には選択されたアクターにメッセージをブロードキャストするためにワイルドカードを指定することができます。
// will look all children to serviceB with names starting with worker
context.actorSelection("/user/serviceB/worker*")
// will look up all siblings beneath same supervisor
context.actorSelection("../*")
メッセージは ActorSelection を使っても送ることができます。 ActorSelection のパスは配信するメッセージごとに探索が行われます。 アクターを探索結果として得られなかった場合はメッセージは破棄されます。
ActorSelection に対応する ActorRef を取得するためには、selectionに対してメッセージを送信し、 アクターから応答を受け取るために sender() の参照を利用してください。全てのアクターは組み込みの Identify というメッセージを理解して、 ActorRef への参照を含む ActorIdentity というメッセージを自動的に応答として返します。このメッセージはアクターによって特別な処理が行われ、具体的な名前による探索が失敗した場合(例えば、ワイルドカードではないパス要素が生存しているアクターと対応していなかった場合)には、偽の結果が生成されます。このことは応答メッセージの到達が保障されていることを意味していないことに注意してください。応答も通常のメッセージです。
import akka.actor.{ Actor, Props, Identify, ActorIdentity, Terminated }
class Follower extends Actor {
val identifyId = 1
context.actorSelection("/user/another") ! Identify(identifyId)
def receive = {
case ActorIdentity(`identifyId`, Some(ref)) =>
context.watch(ref)
context.become(active(ref))
case ActorIdentity(`identifyId`, None) => context.stop(self)
}
def active(another: ActorRef): Actor.Receive = {
case Terminated(`another`) => context.stop(self)
}
}
:clas:`ActorSelection` の resolveOne というメソッドを使うことによっても ActorSelection に対応する ActorRef を取得することができます。このメソッドは指定したアクターが存在した場合に該当する ActorRef を Future として返します。指定したアクターが存在しない場合や timeout で指定した時間内に解決が完了しなかった場合には [[akka.actor.ActorNotFound]]が失敗として戻されます。
remoting が有効な場合、リモートのアクターのアドレスも探索することができます。
context.actorSelection("akka.tcp://app@otherhost:1234/user/serviceB")
アクターの探索のサンプルデモは Remoting Sample にあります。
メッセージと不変性
重要 : メッセージはどんな種類のオブジェクトでも構いませんが、不変である必要があります。Scalaは不変性を(今のところ)強制できないのでこれは習慣にする必要があります。StringやInt、Booleanといったプリミティブは常に不変です。これら以外でScalaで推奨される手法は(明示的に状態を公開しない限りにおいては)不変なcase classを使うことです。case classを使うとメッセージの受信側でパターンマッチを使えるので大変便利です。
以下はこのサンプルコードです。
// define the case class
case class Register(user: User)
// create a new case class message
val message = Register(user)
メッセージの送信
メッセージはアクターの以下に挙げるメソッドのいずれかを使って送信することができます。
!は"fire-and-forget"を意味します。つまり、メッセージを非同期に送信し、直ちに制御を戻すことができます。tellという別名もあります。?はメッセージを非同期に送信し、利用可能な戻り値を表現したFutureを返します。askという別名もあります。
メッセージの順序は基本的に送信者ごとに保障されます。
注釈
timeout を追跡しなければならないため、ask を使う場合にはパフォーマンス上の影響があります。 Promise と ActorRef を連携させるためにいくつかのことをやらなければならないし、それがリモートであっても到達可能にする必要があります。パフォーマンスのためには常に tell を使うことが望ましく、 ask を使うのは本当に必要な時だけにすべきです。
Tell: Fire-forget
メッセージを送る場合、こちらの方が好ましい手段です。メッセージを待つようなブロッキングがありません。この手段を用いることで並列性最大限に生かし、スケーラビリティを得ることができます。
actorRef ! message
Actorの中で呼びだした場合、送信側のアクターの参照が暗黙的にメッセージと一緒に受け渡され、受信側のアクターが sender():ActorRef というメンバーメソッドを使ってこれを利用できます。メッセージを受け取ったアクターはこれを使って、 sender() ! replyMsg という形で元の送信者に応答を返すことができます。
アクター ではない インスタンスから呼び出した場合、デフォルトでは送信者は deadLetters のアクターの参照になります。
Ask: Send-And-Receive-Future
ask パターンはアクターだけではなくfutureも含むパターンです。よって ActorRef のメソッドとしてではなくパターンとして使う形で提供されています。
import akka.pattern.{ ask, pipe }
import system.dispatcher // The ExecutionContext that will be used
final case class Result(x: Int, s: String, d: Double)
case object Request
implicit val timeout = Timeout(5 seconds) // needed for `?` below
val f: Future[Result] =
for {
x <- ask(actorA, Request).mapTo[Int] // call pattern directly
s <- (actorB ask Request).mapTo[String] // call by implicit conversion
d <- (actorC ? Request).mapTo[Double] // call by symbolic name
} yield Result(x, s, d)
f pipeTo actorD // .. or ..
pipe(f) to actorD
一般的によく使う組み合わせなので、このサンプルコードでは ask と pipeTo というパターンを一緒に使っています。上記のコードは全てノンブロッキングで非同期だということに注目してください。 ask は :class:Future` を作りますが、for内包表記を使って3つのFutureを組み合わせて別の新しいFutureに合成しています。pipeTo`` はFutureに ``onComplete ハンドラを作って Result に集約された結果を他のアクターに受け渡します。
ask を使うとメッセージは tell を使って受信側のアクターに送信され、 受信側のアクターは Future として値を返すために sender() ! reply を使って応答を返さなければいけません。 ask を実行すると応答を処理するための内部的なアクターが生成されますが、資源がリークさせないように一定時間を経過したらそれが破棄されるようタイムアウトを設ける必要があります。以下の詳細をご覧ください。
警告
Futureで例外が発生した場合、送信者に障害のメッセージを送信する必要があります。これはアクターがメッセージを処理するときに例外をスローしたとしても 自動的行われることはありません。
try {
val result = operation()
sender() ! result
} catch {
case e: Exception =>
sender() ! akka.actor.Status.Failure(e)
throw e
}
アクターがFutureの処理を完了しなかった場合、タイムアウト経過後に AskTimeoutException を返して有効期限切れになります。タイムアウトは次のような優先順位で取得されます。
次のように明示的に与えられた場合
import scala.concurrent.duration._
import akka.pattern.ask
val future = myActor.ask("hello")(5 seconds)
akka.util.Timeout型の暗黙的引数
import scala.concurrent.duration._
import akka.util.Timeout
import akka.pattern.ask
implicit val timeout = Timeout(5 seconds)
val future = myActor ? "hello"
Futureの結果をどのように待つかといったことやFutureに対する操作については future-scala を参照してください。
onComplete や onSuccess 、 onFailure といった Future のメソッドはFutureの処理が完了した時にブロックすることなく通知を受け取るためのコールバックとして利用することができます。
警告
onComplete や onSuccess 、 onFailure といったFutureのコールバックを使う場合、アクターの中ではアクターの参照をリークしてしまわないように注意する必要があります。例えば、コールバックの中で外側のアクターのメソッドを呼び出したりアクターの状態にアクセスしてはいけません。コールバックは外側のアクターに対して並行に実行されるので、これらはアクターのカプセル化を破壊し、同期関連のバグやレースコンディションを引き起こします。残念なことに今のところこれらの不正なアクセスをコンパイル時に検知する方法がありません。 アクターと共有可変状態 も参照してください。
メッセージの転送
あるアクターが別のアクターへメッセージを転送することができます。これはメッセージが'仲介者'を経由した後でも元の送信者のアドレスや参照が維持されるということです。これはアクターをルーターやロードバランサ、レプリケイターといった用途で使う場合、便利です。
target forward message
メッセージの受信
アクターはメッセージを受信するために receive というメソッドを実装する必要があります。
このメソッドの戻り値は PartialFunction になっていて、その中でメッセージはScalaのパターンマッチを使って'match/case'句の中のそれぞれ異なるmatch句にmatchさせることができます。
import akka.actor.Actor
import akka.actor.Props
import akka.event.Logging
class MyActor extends Actor {
val log = Logging(context.system, this)
def receive = {
case "test" => log.info("received test")
case _ => log.info("received unknown message")
}
}
メッセージへの応答
メッセージに応答を返した場合、 sender() というメソッドを使ってActorRefを取得することができます。そのActorRefに対して sender() ! replyMsg という形で応答を返すことができます。後で応答を返すためにActorRefを保存しておいたり、他のアクターに受け渡すこともできます。送信者がいない場合(アクターの外からメッセージを送信した場合やFutureのコンテクストの中)、デフォルトの送信者は 'dead-letter' のアクターの参照になります。
case request =>
val result = process(request)
sender() ! result // will have dead-letter actor as default
受信タイムアウト
ActorContextsetReceiveTimeout は非アクティブ時のタイムアウトを定義し、その時間を経過すると ReceiveTimeout が送信されるトリガになります。このタイムアウトが設定されている時、 receive 関数は akka.actor.ReceiveTimeout を処理することができなければいけません。このタイムアウトの最小値は1ミリ秒です。
受信タイムアウトが発生してから ReceiveTimeout メッセージが他の既にキューに入っているメッセージの後に追加されることに注意してください。つまり、あらかじめメソッドを通じて設定した待ち時間ちょうどに受信タイムアウトのメッセージを受け取られることは**保障されていません**。
受信タイムアウトは一度設定すると効果として残り続けます。(つまり、非アクティブ時間を経過するごとに継続的にメッセージが送信されます。) Duration.Undefined を設定することでこの機能を閉じることができます。
import akka.actor.ReceiveTimeout
import scala.concurrent.duration._
class MyActor extends Actor {
// To set an initial delay
context.setReceiveTimeout(30 milliseconds)
def receive = {
case "Hello" =>
// To set in a response to a message
context.setReceiveTimeout(100 milliseconds)
case ReceiveTimeout =>
// To turn it off
context.setReceiveTimeout(Duration.Undefined)
throw new RuntimeException("Receive timed out")
}
}
NotInfluenceReceiveTimeout をmix-inしたメッセージはタイマーのリセットを行いません。外部に対して非アクティブだった場合に ReceiveTimeout を起こしたいが、内部の活動からは影響を受けたくない場合にこれが役に立つことがあります。例えば、スケジューラの定期的なメッセージ等です。
アクターの停止
アクターは ActorContext``や ``ActorSystem 等の``ActorRefFactory`` が持つ stop というメソッドを呼び出すことで停止できます。通常はコンテクストでは自分自身や自分の子供のアクターを停止し、アクターシステムではトップレベルのアクターを停止します。実際にアクターが終了するのは非同期に行われ、 stop メソッドはアクターが停止する前に制御を戻します。
class MyActor extends Actor {
val child: ActorRef = ???
def receive = {
case "interrupt-child" =>
context stop child
case "done" =>
context stop self
}
}
アクターを停止する前に処理しようとしていたメッセージがあれば、それは処理されますが、その後にメールボックスに入ってきたメッセージは処理されません。デフォルトではこれらのメッセージは ActorSystem の deadLetters に送られますが、これはメールボックスの実装に依存します。
アクターの停止には二つのステップがあります。まず、アクターは自分のメールボックスの処理を中止して自分の子アクターに停止コマンドを送信します。それから最後のものがなくなるまで内部の終了通知の処理を続け、最終的に自分自身を停止します。( postStop を呼び出し、メールボックスをダンプしてから DeathWatch しながら Terminated メッセージを発行します。)この手順はアクターシステムのサブツリーを秩序のある方法で停止し、停止コマンドを葉に伝播させてから確認応答を停止したアクターのスーパーバイザーに返していきます。もしいずれかのアクターが応答しなかった場合(例えば、メッセージを長時間処理していて停止コマンドを受信できない場合)、この全体の処理が止まってしまいます。
ActorSystem.terminate を呼びだすと、システムガーディアンアクターが停止され、前述の処理によってシステム全体が正しく停止されます。
postStop フックは、アクターが完全に停止した後に呼び出されます。これにより、リソースのクリーンアップが可能になります。
override def postStop() {
// clean up some resources ...
}
注釈
アクターの停止は非同期であるため、停止した子の名前をすぐに再利用することはできません。これは InvalidActorNameException になります。代わりに、停止しようとしているアクターを watch し、最終的に到着する Terminated メッセージに反応して置換を行います。
毒薬
アクターに akka.actor.PoisonPill メッセージを送ることもできます。このメッセージが処理されると、アクターは停止します。 PoisonPill は通常のメッセージとしてエンキューされ、すでにメールボックスにキューイングされているメッセージの後に処理されます。
グレースフルな停止
gracefulStop は、終了を待つ必要がある場合や、いくつかのアクタの順序付けられた終了を構成する必要がある場合に便利です。
import akka.pattern.gracefulStop
import scala.concurrent.Await
try {
val stopped: Future[Boolean] = gracefulStop(actorRef, 5 seconds, Manager.Shutdown)
Await.result(stopped, 6 seconds)
// the actor has been stopped
} catch {
// the actor wasn't stopped within 5 seconds
case e: akka.pattern.AskTimeoutException =>
}
object Manager {
case object Shutdown
}
class Manager extends Actor {
import Manager._
val worker = context.watch(context.actorOf(Props[Cruncher], "worker"))
def receive = {
case "job" => worker ! "crunch"
case Shutdown =>
worker ! PoisonPill
context become shuttingDown
}
def shuttingDown: Receive = {
case "job" => sender() ! "service unavailable, shutting down"
case Terminated(`worker`) =>
context stop self
}
}
gracefulStop() が正常に返されると、アクターの postStop() フックが実行されます: postStop() の終了と gracefulStop() の完了の間には順次呼び出しの隙間があります。
上記の例では、カスタムの Manager.Shutdown メッセージがターゲットのアクターに送信され、アクターを停止するプロセスが開始されます。 これを実現するのに PoisonPill を使うこともできますが、ターゲットのアクターを停止する前に他のアクターとのやり取りを行う可能性がわずかながらあります。 単純なクリーンアップのタスクは postStop で処理できます。
警告
アクターが停止することと、その名前の登録が抹消されることは、お互いに非同期で起こる別々のイベントであることに注意してください。したがって、 gracefulStop() が返された後でも、まだ名前が使用中なのを見ることがあるかもしれません。 適切に登録の解除を保証するには、あなたが管理するスーパーバイザ内から名前を再利用するだけで、class:Terminated メッセージに反応するだけで、つまりトップレベルのアクターではありません。
Become/Unbecome
更新
Akkaは、実行時にアクターのメッセージループ(例:その実装)をホットスワップすることをサポートしています。これを行うためには、アクターの中から `` context.become`` メソッドを呼び出します。 :meth: become は、新しいメッセージハンドラの実装となる ` PartialFunction [Any、Unit] ` を受け取ります。 ホットスワップされたコードはスタックに保持され、プッシュしたりポップしたりすることができます。
警告
Supervisorによってアクターが再起動されたときには元の振る舞いに戻ってしまうことに注意してください。
アクターの振る舞いをホットスワップするためには become を使用します。
class HotSwapActor extends Actor {
import context._
def angry: Receive = {
case "foo" => sender() ! "I am already angry?"
case "bar" => become(happy)
}
def happy: Receive = {
case "bar" => sender() ! "I am already happy :-)"
case "foo" => become(angry)
}
def receive = {
case "foo" => become(angry)
case "bar" => become(happy)
}
}
:meth: become`メソッドの変種は便利で例えば有限状態マシン (FSM、この例は、`Dining Hakkers`を参照してください_) を実装するなど、さまざまな目的に役立ちます。 有限状態マシンは現在の動作(つまり動作スタックの先頭)を置き換えます。つまり、:meth: `unbecome を使わなくても、常に次の動作が明示的に決まります。
:meth: become のもう一つの使い方として、動作スタックの先頭を置き換えずにスタックの先頭に追加するというものがあります。 この場合、「ポップ」操作の数(すなわち :meth: unbecome)が長期的に「プッシュ」の数に一致するように注意する必要があります。そうでなければ、メモリリークが発生します(この動作はデフォルトではないのはこれが理由です)。
case object Swap
class Swapper extends Actor {
import context._
val log = Logging(system, this)
def receive = {
case Swap =>
log.info("Hi")
become({
case Swap =>
log.info("Ho")
unbecome() // resets the latest 'become' (just for fun)
}, discardOld = false) // push on top instead of replace
}
}
object SwapperApp extends App {
val system = ActorSystem("SwapperSystem")
val swap = system.actorOf(Props[Swapper], name = "swapper")
swap ! Swap // logs Hi
swap ! Swap // logs Ho
swap ! Swap // logs Hi
swap ! Swap // logs Ho
swap ! Swap // logs Hi
swap ! Swap // logs Ho
}
Scalaのアクターは、メモリを誤ってリークすることなくネストされた受信を行います。
以下の ネスとしない受信の例 <@github@/akka-docs/rst/scala/code/docs/actor/UnnestedReceives.scala> を参照してください。
Stash
stash() を呼び出すと、現在のメッセージ(アクターが最後に受け取ったメッセージ)がアクターの隠しに追加されます。 これは通常、アクターのメッセージハンドラーでデフォルトのケースを処理して、他のケースでは処理されないメッセージを隠すときに呼び出されます。 同じメッセージを2回隠すのは不正です。 これを行うと、 `` IllegalStateException``がスローされます。 stashはまた境界がついているかもしれません。その場合、 `` stash() を呼び出すと容量違反につながり、結果として `` StashOverflowException``が発生します。 stashの容量はメールボックスの設定の "stash-capacity"設定( `` Int)を使って設定できます。
注釈
`` Stash``は、 `` RequiresMessageQueue [DequeBasedMessageQueueSemantics] `` というマーカートレイトを拡張しています。このマーカートレイトは、システムにアクターにキューベースのメールボックス実装を自動的に選択するように要求します。 メールボックスをより詳細に制御したい場合は、メールボックス メールボックス のドキュメントを参照してください。
以下は実際に Stash を使った例です。
import akka.actor.Stash
class ActorWithProtocol extends Actor with Stash {
def receive = {
case "open" =>
unstashAll()
context.become({
case "write" => // do writing...
case "close" =>
unstashAll()
context.unbecome()
case msg => stash()
}, discardOld = false) // stack on top instead of replacing
case msg => stash()
}
}
stash() を呼び出すと、現在のメッセージ(アクターが最後に受け取ったメッセージ)をアクターの隠れた場所に追加します。 これは通常、アクターのメッセージハンドラーでデフォルトのケースを処理するときに、他のケースで処理しないメッセージを蓄えておきたいときに呼び出します。 同じメッセージを2回蓄えるのは不正です。 これを行うと、 IllegalStateException がスローされます。 stashは容量を持っているので、 stash()``を呼び出したときに容量違反になることがあり、その場合 `` StashOverflowException が発生します。 stashの容量はメールボックスの設定の "stash-capacity" という項目(`` Int`` を指定します)を使って設定できます。
unstashAll() を呼び出すと、メールボックス(もしあれば)の容量に達するまで、stashからのメッセージをアクターのメールボックスに追加します(stashからのメッセージはメールボックスに前から追加されます)。 容量を持つメールボックスがオーバーフローした場合、 MessageQueueAppendFailedException がスローされます。 stashは、 unstashAll()` を呼び出した後は空であることが保証されています。
stashは scala.collection.immutable.Vector を使っています。 そのため、非常に多数のメッセージを蓄えていたとしてもパフォーマンスに大きな影響を与えません。
警告
Stash トレイトは、 preRestart コールバックをオーバーライドするトレイト/クラスの前に Actor トレイト(もしくはそのサブクラス)にミックスインしなければならないことに注意してください。 これは、 MyActor が preRestart をオーバーライドしている場合に、 Actor with MyActor with Stash という書き方ができないということです。
stashは、メールボックスとは異なり、一時的なアクター状態の一部であることに注意してください。 したがって、同じような特性を持つその他のアクターの状態と同様に管理する必要があります。 :class: Stash トレイトの:meth:preRestart の実装は、 unstashAll() を呼び出します。これは、通常、望ましい動作です。
注釈
アクターが容量の境界がないstashを使うようにしたい場合は、代わりに UnboundedStash を使います。
アクターの強制停止
Kill メッセージを送ることによってアクターを強制停止することができます。 このメッセージを受け取ると、アクターは ActorKilledException をスローし、失敗をトリガーします。 アクターは操作を中断し、スーパーバイザーに失敗を処理する方法を尋ねます。 これはアクターがレジュームされたり、再起動されたり、完全に停止させられたりすることを意味します。 詳細は、スーパービジョンが意味するもの を参照してください。
Kill` メッセージは以下の様に使用します。
// kill the 'victim' actor
victim ! Kill
アクターと例外
アクターがメッセージを処理している間に、データベース例外のような例外が発生することがあります。
メッセージへの影響
メッセージの処理中に例外がスローされた場合(つまり、メールボックスから取り出され、現在の動作に引き渡されていた場合)、このメッセージは失われます。それがメールボックスに戻されないということを理解しておくことが重要です。したがって、メッセージの処理を再試行したい場合は、例外をキャッチして自分で処理し、フローを再試行する必要があります。システムがライブロックしないようにするため、再試行回数に制限を書けるようにしてください(処理を行わないのにCPUサイクルを多く消費してしまいまう)。 PeekMailbox pattern を用いるという手もあります。
メールボックスへの影響
メッセージの処理中に例外がスローされても、メールボックスには何の影響もありません。アクターが再起動すると、同じメールボックスが利用されます。メールボックスの中のすべてのメッセージもそこにあります。
アクターへの影響
アクター内のコードが例外をスローすると、そのアクターは中断され、スーパーバイザーの処理が開始します(:ref: supervision を参照してください)。アクターはスーパーバイザーの決定に従って、(何も起きなかったのと同じように)レジュームしたり、再起動したり(内部状態を一掃してゼロから開始します)、停止したりします。
PartialFunction を連鎖してアクターを拡張する
いくつかのアクター間で共通の振る舞いを共有したり、複数の小さな関数から1つのアクターの振る舞いを合成することが有用なことがあります。アクターの :meth: receive メソッドの戻り値である ` Actor.Receive` は ` PartialFunction [Any、Unit] ` の型エイリアスであり、部分関数は PartialFunction#orElse メソッドを使って合成できるので、これは可能です。必要なだけ多くの関数を連鎖させることができますが、同じ型のメッセージ処理できる関数を合成する際に重要な "first-match" wins という法則に注意してください。
たとえば、 Producers と Consumers のどちらかのアクターのセットがあるときに、一つのアクターに両方の動作を共有させることが理にかなっていることがあります。これは、振る舞いトレイトに切り出して、その部分関数の組み合わせとしてアクターの :meth:receive を実装することによって、コードを重複させる必要なしに、容易に達成することができます。
trait ProducerBehavior {
this: Actor =>
val producerBehavior: Receive = {
case GiveMeThings =>
sender() ! Give("thing")
}
}
trait ConsumerBehavior {
this: Actor with ActorLogging =>
val consumerBehavior: Receive = {
case ref: ActorRef =>
ref ! GiveMeThings
case Give(thing) =>
log.info("Got a thing! It's {}", thing)
}
}
class Producer extends Actor with ProducerBehavior {
def receive = producerBehavior
}
class Consumer extends Actor with ActorLogging with ConsumerBehavior {
def receive = consumerBehavior
}
class ProducerConsumer extends Actor with ActorLogging
with ProducerBehavior with ConsumerBehavior {
def receive = producerBehavior.orElse[Any, Unit](consumerBehavior)
}
// protocol
case object GiveMeThings
final case class Give(thing: Any)
継承の代わりに、合成を使うことで同じパターンを適用することもできます。 この場合、デリゲートの部分関数を使って単純に receive 関数を合成します。
初期化のパターン
アクターには沢山のライフサイクルフックがあり、さまざまな初期化パターンを実装するための便利なツールキットを提供します。 ActorRef の存続期間中、アクターはいくつかの再始動を行っている可能性があります。古いインスタンスは新しいものに置き換えられ、 `` ActorRef``だけを見る外部の観察者にはわかりません。
新しいインスタンスは「インカネーション」だと思う人もいるかもしれません。初期化はアクターのすべてのインカーネーションに対して必要であることもありますが、場合によっては、 ActorRef が作成されたときの最初のインスタンスの誕生時にのみ初期化を行う必要があることもあります。次のセクションでは、異なる初期化の必要に応じたパターンを紹介します。
コンストラクタを使った初期化
コンストラクタを使った初期化には様々な利点があります。まず第一に、アクターインスタンスの存続期間中に変化しない状態を格納するために ``val``フィールドを使用することができるようになり、アクターの実装がより堅牢になります。コンストラクタはアクターのインカネーションごとに呼び出されるため、アクタの内部は常に適切な初期化が行われたとみなすことができます。しかし、この方法の欠点でもあります。再起動時に内部の再初期化を避けたい場合があるためです。たとえば、再起動をまたいで子アクターを保持すると便利なことがあります。次のセクションでは、このケースのパターンを示します。
preStart による初期化
アクターの preStart() メソッドは、最初のインスタンスの初期化中、つまり ActorRef の作成時に一度だけ直接的に呼び出されます。再起動の場合、 `` preStart()``は `` postRestart()``から呼び出されるため、オーバーライドしないと、すべてのインカネーションで ``preStart()``が呼び出されます。しかし、 ``postRestart()``をオーバーライドすることで、この動作を無効にし、 ``preStart()``への呼び出しが1つしかないことを保証することができます。
このパターンの便利な使い方の1つは、再起動時に子プロセスの新しい ActorRefs の作成を無効にすることです。これは preRestart() をオーバーライドすることで実現できます:
override def preStart(): Unit = {
// Initialize children here
}
// Overriding postRestart to disable the call to preStart()
// after restarts
override def postRestart(reason: Throwable): Unit = ()
// The default implementation of preRestart() stops all the children
// of the actor. To opt-out from stopping the children, we
// have to override preRestart()
override def preRestart(reason: Throwable, message: Option[Any]): Unit = {
// Keep the call to postStop(), but no stopping of children
postStop()
}
子アクターはまだ 再起動しています が、新しい ``ActorRef``は作成されないということに注目してください。子アクターに同じ原則を再帰的に適用して、 ``preStart()``メソッドがrefの作成時にのみ呼び出されるようにすることができます。
さらに詳しい情報は リスタートが意味するもの を参照してください。
メッセージパッシングによる初期化
たとえば、循環依存が存在する場合など、アクターの初期化に必要なすべての情報をコンストラクタに渡すことが不可能な場合があります。この場合、アクターは初期化メッセージをリッスンし、アクターの初期化後の状態と初期化前の状態をエンコードするために become() または有限ステートマシン状態による遷移を使用する必要があります。
var initializeMe: Option[String] = None
override def receive = {
case "init" =>
initializeMe = Some("Up and running")
context.become(initialized, discardOld = true)
}
def initialized: Receive = {
case "U OK?" => initializeMe foreach { sender() ! _ }
}
アクターが初期化される前にメッセージを受けとる場合、初期化が完了するまでメッセージを保存し、アクターが初期化された後にメッセージを再生する Stash という便利なツールがあります。
警告
このパターンは慎重に使用し、上記のパターンのいずれも該当しない場合にのみ適用してください。潜在的な問題の1つは、メッセージがリモートアクターに送信されると失われる可能性があることです。また、 ActorRef を初期化されていない状態で公開すると、初期化が完了する前にユーザメッセージを受け取るという条件につながる可能性があります。
Contents