
スーパービジョン と モニタリング
この章ではスーパービジョンの背後の概念、基本的な要求、意味論について述べます。これらをどうやって本当のコードに落とし込むかの詳細については、Scala と Java API の対応する章を見てください。
スーパービジョンが意味するもの
アクターシステム にあるようにスーパービジョンはアクターの依存関係を記述します。スーパ^バイザーはタスクを部下に移譲し、そしてその障害に対応する必要があります。部下が障害を検知したとき (つまり、例外を投げたとき) 、部下は自分自身と自分の部下すべてを停止し、スーパーバイザーにメッセージを送り、障害を伝えます。スーパバイザーの対象の作業の性質と障害の性質によって、スーパーバイザーは次の 4 つのオプションを選択できます。
部下を再開し、蓄積されている内部状態を維持する。
部下をリスタートし、蓄積された内部状態をクリアにする。
部下を永久に停止する。
障害を上位にエスカレートする。したがって自分自身が失敗になる。
アクターをスーパービジョンの階層の一部としてみることは重要であり、それにより 4 つめの選択肢 (あるスーパーバイザーもまた別の上位のスーパーバイザーの部下である) を説明できますし、また最初の3つについても密接な関係があります。アクターの再開はその部下すべてを再開しますし、アクターのリスタートはその部下のすべてをリスタートしますし (ただし、次に述べる詳細を見てください) 、同様にアクターの停止はすべての部下を停止しようとします。 Actor クラスにあるフックの preRestart のデフォルトの動作は、リスタートの前にすべての子供を停止することに注意するべきです。ただし、このフックはオーバーライドが可能であり、フックが実行された後に残ったすべての子供へに対して再帰的なリスタートが適用されます。
各スーパーバイザーは、発生する可能性のあるすべての障害 (つまり例外) を上記に挙げた4つの選択肢の1つに変換する関数で設定されます。特に、この関数は失敗したアクターのアイデンティティを入力にとりません。十分に柔軟に見えないような構造の例を挙げるのはとても簡単であり、例えば、異なる部下に対して異なる戦略を適用したい場合があります。この場合、スーパービジョンが障害を再帰的にハンドリングする形式であることを理解しておくことが不可欠です。1つの階層で沢山のことをしようとすと、理解するのが難しくなります。したがってこの場合、推奨されるのはスーパービジョンの階層を追加することです。
Akka は "親のスーパービジョン" と呼ばれる特定の形式を実装します。アクターは他のアクターによって生成されます。 ただし、トップレベルのあくたーはライブラリによって生成されます。 そして生成された各アクターはその親によって監督されます。この制約はアクターのスーパービジョンの階層を暗黙的にし、設計上の意思決定を行いやすくします。これによりアクターは孤立したり、外部のスーパーバイザーに補足されたりすることが無いことを保証していることに注意してください。そうでなければ、不意に補足したりするかもしれません。さらに、アクターアプリケーション (のサブツリー) の自然で整理されたシャットダウンの手順も獲得できます。
警告
スーパービジョンに関する親子間の通信は、ユーザーメッセージとは隔離されたメールボックスを持つ特別なシステムメッセージ上で行われます。これはスーパービジョンに関するイベントが通常のメッセージとの間で決定論的に順序付けられないことを示唆しています。一般的に、ユーザーは通常のメッセージと障害の検知の順番に影響を与えることはできません。詳細とサンプルについては ディスカッション: メッセージの順序 のセクションを見てください。
トップレベルのスーパーバイザー
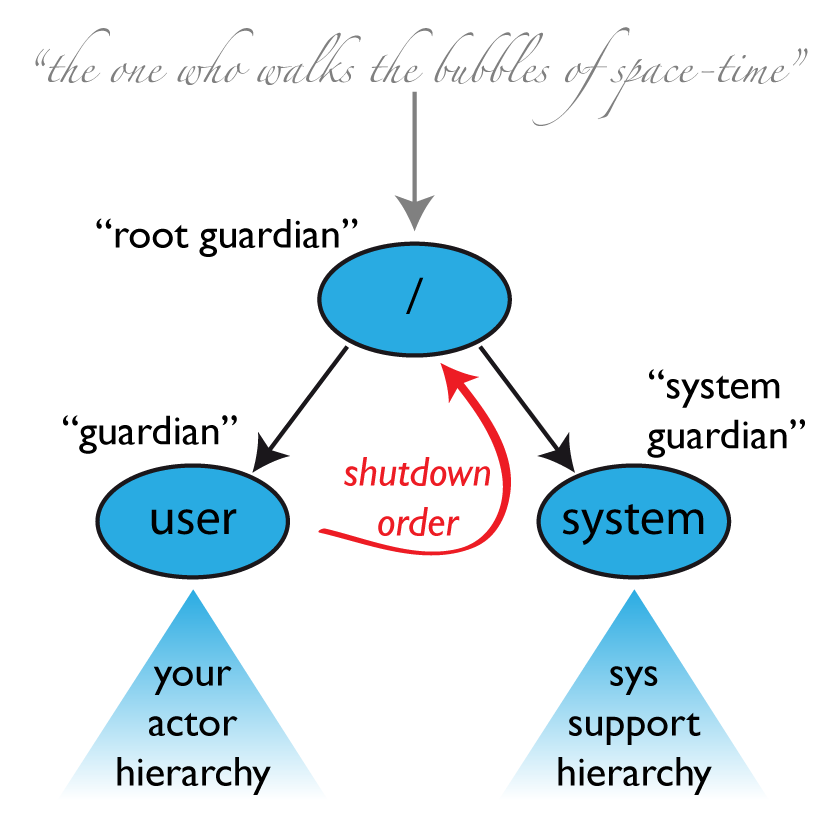
アクターシステムは生成時に最低でも3つのアクターを開始します。そのイメージを上に示しています。アクターパスの結果に関する詳細な情報は アクターパスのトップレベルスコープ を見てください。
/user: ガーディアンアクター
ユーザーが作成するアクターのすべての親となるおそらくは最も影響のある、"/user" という名前のガーディアンです。 system.actorOf() を使って生成されたアクターはこのアクターの子供になります。これはすなわち、このガーディアンが停止すると、システム内のすべての通常のアクターがシャットダウンされることを意味します。また、このガーディアンのスーパーバイザー戦略はトップレベルの通常のアクターのスーパーバイザーになることも意味します。 Akka 2.1 からこの設定に akka.actor.guardian-supervisor-strategy を使うことができるようになりました。これは SupervisorStrategyConfigurator の完全修飾クラス名を取ります。ガーディアンが失敗をエスカレートすると、ルートガーディアンの対応によりガーディアンは停止し、その結果としてすべてのアクターシステムはシャットダウンするでしょう。
/system: システムガーディアン
この特別なガーディアンはすべての通常のアクターが停止していてもロギングをアクティブにしながら整理されたシャットダウン手順を達成するために導入され、アクター自体にロギングが実装されている場合でも動作します。これはシステムガーディアンがユーザーガーディアンを監視し、 Terminated メッセージを受け取ったら自身をシャットダウンすることで実現されます。トップレベルのシステムアクターは、 ActorInitializationException と ActorKilledException を除いたすべての Exception 型に対して無期限にリスタートするスーパーバイザー戦略を用いています。これで問題のある子供は停止されます。その他の例外がエスカレートされた場合は、全アクターシステムがシャットダウンされるでしょう。
/: ルートガーディアン
ルートガーディアンは "トップレベル"" と呼ばれるアクターの祖父にあたり、 アクターパスのトップレベルスコープ で言及された SupervisorStrategy.stoppingStrategy を使っている全ての特別なアクターを監督します。その目的は、あらゆる型の Exception の発生に対して子供を停止させることにあります。その他の全ての Throwable がエスカレートされますが誰によってでしょう? あらゆる実体のアクターはスーパーバイザーを持っていますが、ルートガーディアンのスーパバイザーは実体のアクターではありません。これは "泡の外" を意味してして、 "泡を歩く者" と呼んでいます。これは人工的な ActorRef であり、トラブルの最初の兆候で子供を停止させ、ルートガーディアンが完全に停止 (再帰的に全ての子供も停止する) するとすぐに、アクターシステムの isTerminated ステータスを true に設定します。
リスタートが意味するもの
特定のメッセージの処理にアクターが失敗したとき、 その失敗の原因は 3 つのカテゴリに分類されます。
特定の受信メッセージに対する、システム的な (すなわちプログラム上の) エラー
メッセージ処理中に使用したある外部リソースの (一時的な) 障害
アクターの内部状態の汚染
障害が明確に認識されない限り、3番目の原因を取り除くことはできず、そのため内部状態を空にする必要があるという結論が導かれます。もしスーパーバイザーがその他の子供や自分自身汚染による影響を受けていないと判断する場合、例えばエラーカーネルパターンを意識的に適用するために、子供をリスタートすることが最善です。これは、子供の ActorRef の内部で Actor 配下の新しいインスタンスを生成して、 障害の起きたインスタンスと新しいものを置き換えることで実現します。この能力がアクターを特別な参照で隠蔽する理由の1つです。新しいアクターはそれから自身のメールボックスの処理を再開します。つまり、リスタートは例外とアクター自身の外部から見えず、障害が起きている間に発生したメッセージは再び処理されることはありません。
リスタート中の正確なイベントの順序は次の通りです。
アクターを一時停止 ( 再開するまで通常のメッセージ処理は処理されません ) し、全ての子供も再帰的に一時停止します。
古いインスタンスの
preRestartフック ( デフォルトでは全ての子供に停止リクエストを送信し、postStopを呼び出します ) を 呼び出します。preRestartの中で、 (context.stop()を使って) 停止を要求した全ての子供が実際に停止するまで待機します。この操作は、 全てのアクターの操作がそうであるように、ノンブロッキングなので、 最後に死んだ子供からの停止の通知をもって、次のステップに進むようになるでしょう。オリジナルの提供されたファクトリを再度実行して、新しいアクターのインスタンスを生成します。
新しいインスタンスの
postRestartメソッド ( デフォルトではpreStartも呼ばれます ) を実行します。リスタート要求をステップ3 で死ななかった全てのアクターに送信します。リスタートした子供はステップ2 から再帰的に同じ処理を行います。
アクターを再開します。
ライフサイクルモニタリングが意味するもの
注釈
Akka のライフサイクルモニタリングは、通常 DeathWatch を指しています。
上記で述べたような親と子の間の特別な関係とは対照的に、各アクターはあらゆる他のアクターを監視するかもしれません。アクターは完全に生きている状態で生成され、リスタートは影響を受けるスーパーバイザーの外部から見えないため、モニタリングが可能な唯一の状態変更は、生存から死亡への変化のみです。このようにモニタリングはあるアクターを別のアクターと結びつけるために使用し、別のアクターの終了に対して反応します。障害に対して反応するスーパービジョンとは対照的です。
ライフサイクルモニタリングは、モニタリングをしているアクターが受け取る Terminated メッセージを使って実装します。このデフォルトの動作は、別途処理しなければ、特定の DeathPactException をスローします。 Terminated メッセージの監視を開始するために、 ActorContext.watch(targetActorRef) を実行します。監視を停止するには、 ActorContext.unwatch(targetActorRef) を実行します。1つの重要な性質に、モニタリング要求と、対象の停止の発生の順序に関係なくメッセージが配信されることがあります。つまり、登録時に対象がすでに死んでいたとしても、メッセージが取得できる場合があります。
モニタリングは、スーパーバイザーが単純に子供をリスタートしたり停止したりできない状況で特に有用です。例えば、アクター初期化中の障害などの場合などです。そのような場合、子供を監視しておき、再生成するか、あるいは、しばらく経ってからリトライするようにスケジュールするべきです。
他によくあるケースとして、アクターが外部リソースがないために失敗させたい場合があります。外部リソースは自身の子供のどれかということもありえます。第三者が 子の system.stop(child) メソッドを呼ぶか、 あるいは子に PoisonPill メッセージを送信すると、 スーパーバイザーに影響を与えるでしょう。
BackoffSupervisor パターンによる遅延リスタート
組み込みのパターンとして提供される akka.pattern.BackoffSupervisor はいわゆる 指数関数的なバックオフスーパーバイザー戦略 を実装し、失敗からリスタートするまでの時間を増やしながらアクターを再び開始していきます。
このパターンは開始されたアクターがある外部リソースが使用できないなどの理由で失敗し [1] 、ある時点で再度スタートアップが必要となる場合に有用です。このパターンが有用となる主要な例の1つは、 PersistentActor が 永続性障害によって (停止して) 失敗する場合です。 これは データベースがダウンしていたり過負荷な状態になっていて、そのような状況で 永続性アクターが開始する前に、回復のために少しの時間を設けることを意図しています。
| [1] | 障害は アクターの停止とクラッシュによる2種類の方法で示されます。 |
次の Scala のスニペットは バックオフスーパーバイザーの作成方法を紹介しています。このスーパーバイザーは与えられたエコーアクターを障害によって停止したら、再開までの間隔を 3秒, 6秒, 12秒, 24秒, そして最後は 30秒と増やしていきます。
val childProps = Props(classOf[EchoActor])
val supervisor = BackoffSupervisor.props(
Backoff.onStop(
childProps,
childName = "myEcho",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // adds 20% "noise" to vary the intervals slightly
))
system.actorOf(supervisor, name = "echoSupervisor")
上記はこの Java コードと同等です。
import scala.concurrent.duration.Duration;
final Props childProps = Props.create(EchoActor.class);
final Props supervisorProps = BackoffSupervisor.props(
Backoff.onStop(
childProps,
"myEcho",
Duration.create(3, TimeUnit.SECONDS),
Duration.create(30, TimeUnit.SECONDS),
0.2)); // adds 20% "noise" to vary the intervals slightly
system.actorOf(supervisorProps, "echoSupervisor");
バックオフ間隔を少々分散させるために、 randomFactor を使うことを強く推奨します。これは複数のアクターが正確に同時にリスタートするを避けるためです。例えば、データベースのような共有リソースが止まって複数のアクターが停止し、同じ設定の間隔の後同時にリスタートします。リスタートの間隔にランダム性を追加することで、アクターはわずかに異なる時点で開始するので、アクセスを行うリカバリ中の共有データベースやその他のリソースへのトラフィックの急激な増加を避けることができるでしょう。
akka.pattern.BackoffSupervisor アクターも、アクターがクラッシュし、スーパビジョン戦略がリスタートすることを決定したときに、遅れてリスタートするように設定されています。
次の Scala のスニペットは バックオフスーパーバイザーの作成方法を紹介しています。このスーパーバイザーは与えられたエコーアクターがある例外のためにクラッシュしたら、再開までの間隔を 3秒, 6秒, 12秒, 24秒, そして最後は 30秒と増やしていきます。
val childProps = Props(classOf[EchoActor])
val supervisor = BackoffSupervisor.props(
Backoff.onFailure(
childProps,
childName = "myEcho",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // adds 20% "noise" to vary the intervals slightly
))
system.actorOf(supervisor, name = "echoSupervisor")
上記はこの Java コードと同等です。
import scala.concurrent.duration.Duration;
final Props childProps = Props.create(EchoActor.class);
final Props supervisorProps = BackoffSupervisor.props(
Backoff.onFailure(
childProps,
"myEcho",
Duration.create(3, TimeUnit.SECONDS),
Duration.create(30, TimeUnit.SECONDS),
0.2)); // adds 20% "noise" to vary the intervals slightly
system.actorOf(supervisorProps, "echoSupervisor");
akka.pattern.BackoffOptions はバックオフスーパーバイザーアクターの振る舞いをカスタマイズするために使用します。以下にいくつか例を挙げます。
val supervisor = BackoffSupervisor.props(
Backoff.onStop(
childProps,
childName = "myEcho",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // adds 20% "noise" to vary the intervals slightly
).withManualReset // the child must send BackoffSupervisor.Reset to its parent
.withDefaultStoppingStrategy // Stop at any Exception thrown
)
上記のコードは、メッセージが正常に処理されバックオフがリセットされたとき、子アクターが親に `` akka.pattern.BackoffSupervisor.Reset`` メッセージを送信するように要求するバックオフスーパバイザを設定しています。また、デフォルトの 停止戦略も使っているので、あらゆる例外に対して子は停止します。
val supervisor = BackoffSupervisor.props(
Backoff.onFailure(
childProps,
childName = "myEcho",
minBackoff = 3.seconds,
maxBackoff = 30.seconds,
randomFactor = 0.2 // adds 20% "noise" to vary the intervals slightly
).withAutoReset(10.seconds) // the child must send BackoffSupervisor.Reset to its parent
.withSupervisorStrategy(
OneForOneStrategy() {
case _: MyException => SupervisorStrategy.Restart
case _ => SupervisorStrategy.Escalate
}))
上記のコードは、 MyException がスローされたら子をバックオフの後にリスタートし、そのほかの例外はエスカレートするようにバックオフスーパーバイザーを設定しています。バックオフは、子が10秒以内に例外を何もスローしない場合にリセットされます。
One-For-One Strategy 対 All-For-One Strategy
Akka には、 OneForOneStrategy と AllForOneStrategy の2つのスーパービジョン戦略があります。両者はスーパビジョン命令 ( 上記 を参照) に対する例外の型から対応付けて設定し、終了の前にどの子供が失敗してもよいかを制限します。両者の違いは、前者は取得した命令を失敗した子供だけに適用し、後者は全ての兄弟に対して適用することにあります。通常、デフォルトであり明示する必要のない、 OneForOneStrategy を使用するべきです。
AllForOneStrategy は子供の全体が互いに強く依存していて、1つの子の障害が他の機能に影響を与える場合、つまり不可分の場合、に適用できます。リスタートではメールボックスは破棄されないので、障害時に子供を終了し、スーパバイザから子供を明示的に (子供のライフサイクルの監視によって) 再作成することがベストとなることがよくあります。 それ以外の場合、他のアクターに対して、リスタートの前にキューに入れられたメッセージが、後で処理されなくなることが問題ないことを確認する必要があります。
all-for-one strategy では、正常に子供を停止 ( つまり、障害による停止ではない場合) しても、他の子供を自動的に停止することにはなりません。これはライフサイクルの監視によって簡単に対応できます。もし Terminated メッセージをスーパーバイザーがハンドリングしなかった場合、 DeathPactException がスローされ、(スーパーバイザーに応じて) リスタートされます。そして、 preRestart のデフォルトの動作で全ての子供が終了します。もちろんこれらを明示的にハンドリングすることもできます。
all-for-one supervisor から一度限りのアクターを生成することは、一時的なアクターによってエスカレートされた障害が永久的に全てに影響することに注意が必要です。もしこれが望ましくないのなら、中間のスーパーバイザーを導入します。これは、サイズが 1 のルーターをワーカーとして宣言することでとても簡単に実現できます。 Routing か Routing を参照してください。
Contents